The workflow for Mapping Senufo, including its database design, underscores the importance of adopting thorough and iterative approaches for development of digital scholarship. Just as scholarship has long grappled with ambiguous information and the possibility of new evidence, so too must the emerging technologies that support new forms of inquiry, analysis, and publication. This project harnesses the power of widely used, open-source tools and platforms that the project team continues to revise and customize as project needs change. This approach yields a project designed to respond to and accommodate ever-expanding data and ever-changing technologies, features key to producing robust and sustainable digital scholarship.
When the Mapping Senufo co-project directors first conceived the project, they imagined a dynamic digital platform to investigate specific time- and place-based data related to individual works (objects or images) identified as Senufo. For example, place names linked to individual works may indicate a location associated with the person credited for the work’s creation, a location where the work was documented, or a location where someone acquired the work.
Mapping Senufo’s early flat spreadsheet of sixty-five records sought to capture the associations between geographic locations and individual works presented in project director Susan Elizabeth Gagliardi’s Senufo Unbound: Dynamics of Art and Identity in West Africa, the book published in conjunction with the Cleveland Museum of Art’s 2015-16 exhibition Senufo: Art and Identity in West Africa. Each row in the project’s flat spreadsheet recorded a reason to associate a work with a place. In most cases the place-based association was fairly straightforward, meaning a single work presented in the book was identified with a single location for a single reason. Complications arose when the project team sought to record data about a single work associated with one place for different reasons or about a single work associated with multiple places.
For example, one work listed in the project’s flat spreadsheet was associated with the town of Lataha because the sculpture was reportedly acquired there. The same work was also associated with Lataha because it appears in a photograph located to the town. The identification of the single sculpture with a single place for two different reasons yielded two records in the flat spreadsheet. The green rows in an image of the flat spreadsheet show the two records, MS_CMA_09 and MS_CMA_10, the latter referencing the same sculpture and relating it to the field photo in record MS_CMA_11.

Another complication with data management in the project’s flat spreadsheet arose when a single work was associated with an ambiguous location. The blue row in our image of the flat spreadsheet corresponds to MS_CMA_62, the record for a figure associated with Niena, a town name that, in the absence of more information, may correspond to four distinct geographic locations.
The records for the sculpture associated with Lataha and the figure associated with Niena made it clear to the project team that a flat spreadsheet could not track multiple relationships among objects, images of objects, and places without generating multiple records and thus repetitive data for a single work.
Flat spreadsheets and relational databases act as repositories for data that users can query. A flat spreadsheet stores all the data in a single table. By contrast, a relational database organizes information into multiple tables that reference one another.
When evaluating digital humanities projects, a critical first step is to focus on the data and conceptualize clearly the data structure before trying to input that data into a digital platform. Thus, before designing a relational database for Mapping Senufo, the project team regularly met to understand the information and relationships integral to the project’s goals. Through our investigation of project data and aims, we recognized that to track and manage data efficiently, including for incorporation into maps and web design, the project required a relational database. More specifically, we decided that separating distinct entities such as works and places into their own tables was necessary to track different kinds of relationships between works and places.
A major benefit of using a relational database, rather than a flat spreadsheet, to organize a large dataset, is that a relational database reduces data repetition by moving certain data into separate tables. In a flat spreadsheet, repetitive data clutters and clouds the one table. Development of separate tables within a relational database makes it possible to link a single table to additional data in secondary tables. For example, the project’s relational database now includes a single record for the sculpture reportedly acquired and photographed in Lataha (1 in Work_Records below). A table for works’ records stores information about the sculpture (Work_Records), another table for places stores information about the town (Places), and still another table lists reasons for linking specific works to particular places (Works_Places).
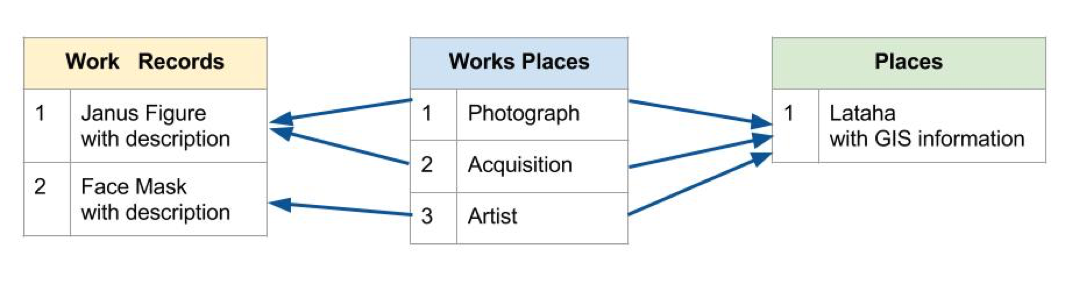
So, as this image from the relational database illustrates, “Photograph” is identified as one reason for connecting the Janus sculpture to Lataha, and “Acquisition” is identified as another reason for the connection. The data about Lataha from the Places table need only be entered once, and can then be associated with multiple records from the Work_Records table or multiple reasons in Works_Places. This example shows the flexibility of the relational database structure to form connections and prevent repetition of data. A more comprehensive discussion of the particular relational database structure developed for Mapping Senufo appears later in this essay.
We also aimed to create a relational database with a more flexible structure to accommodate different data types as well as new data. We accomplished this more flexible structure by creating additional fields for anticipated data types. For example, we included five different date fields in the Works table to account for variations in dating information. Because dates related to works and their locations vary from precise dates to vague information, we designed a database to accommodate four different numeric fields and a generic text field. More specifically, we used four numeric fields, “start date”, “end date”, “by date”, and “not after date”, as well as a generic text field “date information” to record information in a format other than a discrete year.
In addition, we used MySQL to create the relational database, and we designed it for easy integration into CARTO and WordPress to facilitate future development of the project. This design of a relational database with other platforms in mind allows members of the project team to add data in an efficient and consistent manner and then to export that data for transfer to CARTO or WordPress to update data presentations. This approach is consistent with the guidelines of the Emory Center for Digital Scholarship (ECDS) for developing projects that lend themselves to ongoing technical support as platforms change and that give researchers control over the maintenance and publication of their data.
We built the relational database around the early, flat spreadsheet for the project, but we also designed the relational database so it could accommodate hundreds of records as the project expands. As we worked on the relational database design, we presented multiple iterations of the database to the project team for feedback and discussion. As the project develops, we can continue to tailor the relational database to supply expanding datasets to various platforms, including CARTO and WordPress, for data presentation.
The technologies we chose to use reflect:
The selected technologies include the following:
MySQL Community Edition is an open-source Structured Query Language (SQL) database management system (see also My SQL Reference Manual / General Information). MySQL supports creation of large sustainable databases that can contain anything from small data sets with a few records to large data sets with many millions of records. MySQL also works with a variety of other platforms to make the data more flexible. As the most widely used open-source database management system, MySQL provides the benefits of a large user community that shares knowledge about logistics, trouble-shooting and best practices online. Its cost-effectiveness, flexibility, and large user community make MySQL a practical database solution.
Django is a web application framework written in Python that automatically generates an admin interface for data entry. Django’s data-entry interface provides access to MySQL databases for cataloging and presenting the data on the Internet. As an open-source platform, Django has the advantage of community-contributed packages that provide additional function and work like plugins. For Mapping Senufo, we selected the packages django-import-export (0.4.0) and django-queryset-csv (0.3.2) for export of data into CSV files that can be used by other platforms. Data from CSV files imported into CARTO can facilitate map creation. Data from CSV files imported into WordPress can populate information on pages created for individual works.
CARTO is a cloud mapping tool that allows for clear presentation of discrete locations and also interacts well with other web platforms such as WordPress.
WordPress is a tool for the creation of customizable organized websites. Its simple design and many customizable options for the presentation of digital humanities projects make WordPress a good platform for early iterations of Mapping Senufo.
Our relational database allows the Mapping Senufo team to manage, query, analyze, and publish data. The Django Admin interface makes it easy for the project team to enter data into the database and interact with it. Django-import-export and django-queryset-csv, packages of code written by members of the Django user community, integrate with the Admin and support the creation of predefined queries. Export buttons activate these queries and select specific sets of data to populate CSV files for ready import into CARTO and WordPress.
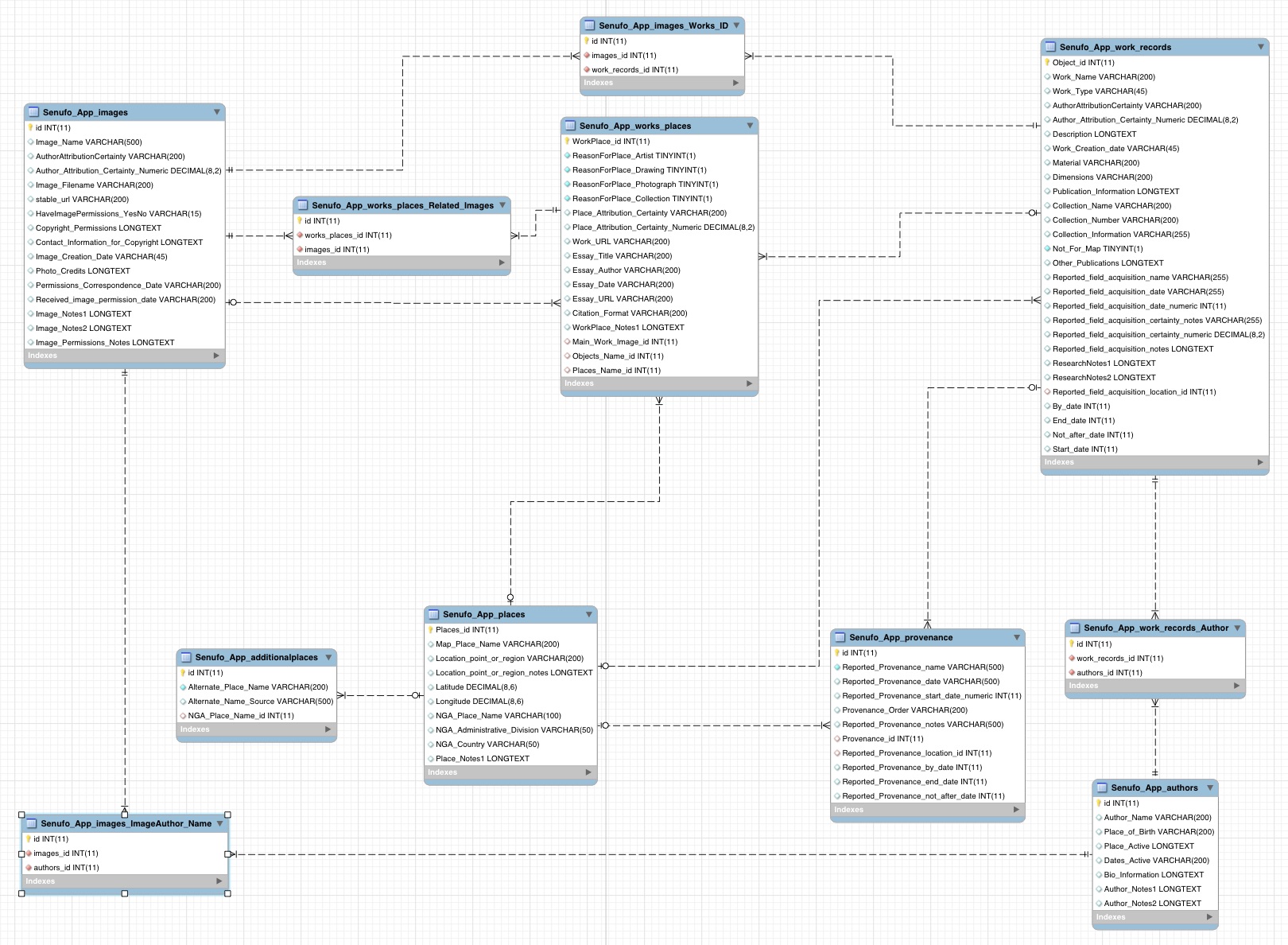
The Mapping Senufo relational database comprises five primary tables: Work_Records, Authors, Places, Images, and Works_Places. Each table captures different information, and the structure reflects a series of specific decisions to accommodate project data.
Work_Records captures specific information about individual works (objects or images) and their histories.
Authors collects data about attributed or actual creators of works. A record in this table may connect a single creator to one or more works from Work_Records or to one or more images from Images.
Places records information about specific places, including latitude and longitude. The field acquisition and provenance fields also connect to records in the Places table.
Images gathers information on digital images of works listed in the Work_Records table and other ancillary images.
The Mapping Senufo relational database also includes two supporting tables, Additional_Places and Provenance.
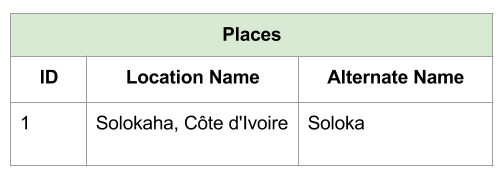
Additional_Places captures variant names and spellings for places in the Places table.
Provenance records data on the provenance of each work in the Work_Records table.
In addition, four linking tables support use of Many-to-Many fields by connecting multiple records in from other tables. The four tables are: Images_ImageAuthor_Name, works_places_Related_Images, Images_Works_ID, and work_records_Author.
The linking tables are not for catalogers or those querying the database to use. Many-to-Many fields rely on a linking table for their underlying structure, and these four tables allow the other major tables to have Many-to-Many fields relating works, places, and images. Stated differently, the linking tables basically function as indexes that track multiple connections between different tables. They must exist for the database to support many-to-many relationships, but a cataloguer does not need to edit them directly because the Django platform is coded to update them appropriately.
Tables in relational databases rely on two special types of fields, Primary Keys and Foreign Keys, to link to one another. A Primary Key is a unique identifier assigned to each record and is required in all tables. A Foreign Key is used to reference a related record in another table and its value is the Primary Key of the related record. As the example of the two records for a single sculpture associated with Lataha for two different reasons demonstrates, the early flat spreadsheet for Mapping Senufo tracked reasons to link works and places and not the works themselves. To resolve the creation of redundant records within the spreadsheet, we created the Works_Places table. This table contains the records that link the single sculpture to Lataha because the sculpture was reportedly acquired and photographed in the town. One Foreign Key references the record for the sculpture in the Work_Records table and another Foreign Key to reference the Places table.
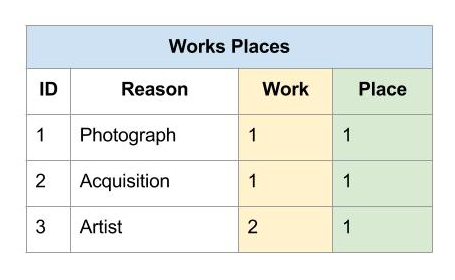
The relationships between fields in different tables can be described by one of two types, One-to-Many or Many-to-Many. The early flat spreadsheet presented a problem when researchers needed to record alternate names for a single place. An example is the village Solokaha, Côte d’Ivoire and its alternate name Soloka.
The problem with using a single column for this information is that it does not allow more than one alternate name. To account for this possibility, we created a separate table called Additional Places in which each record contained a Foreign Key reference to the main Places table.
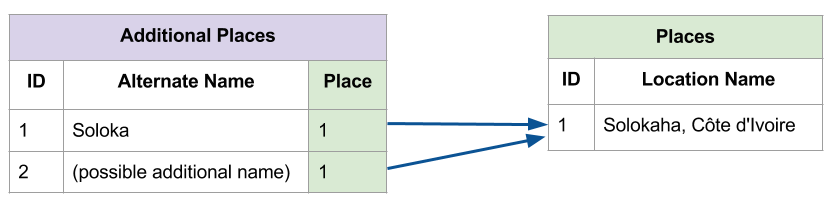
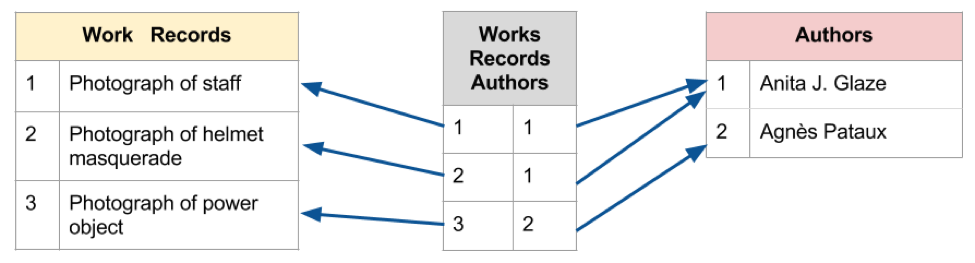
The relationship between Places and Additional_Places is One-to-Many, each place can have many alternative names, but each alternate name is associated with only one place. Another type of relationship, one that is particularly common in humanities datasets, is Many-to-Many. The relationship between works of art and the people who make them is a common example. An artwork may be produced by more than one artist and each artist may create a number of works. To accurately reflect a Many-to-Many relationship between two tables, a third linking table is needed to record each connection. There are several Many-to-Many relationships in the Mapping Senufo dataset such between works and authors, place and works, and works and images. The image below shows a case where one author is connected to two photographs in Work_Records.
With the relational database that we have created, the Mapping Senufo team is gathering data and investigating complex relationships between individual works and geographic locations in a diverse West African region. The kind of data integrity and consistency supported by relational databases could theoretically be achieved with a series of flat spreadsheets scrupulously maintained in Microsoft Excel or another similar program. Maintenance of a series of flat spreadsheets, however, would place an undue burden on researchers by dividing their attention between the subjects they care about and the cumbersome monotony of logging identifying keys. A well-designed relational database with an intuitive interface helps researchers improve and maintain the integrity of their data. It also allows for complex querying to combine and export data. This functionality helps researchers use other tools like CARTO to visualize their conclusions in compelling and interactive ways.
Joanna Mundy and Sara Palmer
23 September 2016
The workflow for Mapping Senufo, including its database design, underscores the importance of adopting thorough and iterative approaches for development of digital scholarship. Just as scholarship has long grappled with ambiguous information and the possibility of new evidence, so too must the emerging technologies that support new forms of inquiry, analysis, and publication. This project harnesses the power of widely used, open-source tools and platforms that the project team continues to revise and customize as project needs change. This approach yields a project designed to respond to and accommodate ever-expanding data and ever-changing technologies, features key to producing robust and sustainable digital scholarship.
When the Mapping Senufo co-project directors first conceived the project, they imagined a dynamic digital platform to investigate specific time- and place-based data related to individual works (objects or images) identified as Senufo. For example, place names linked to individual works may indicate a location associated with the person credited for the work’s creation, a location where the work was documented, or a location where someone acquired the work.
Mapping Senufo’s early flat spreadsheet of sixty-five records sought to capture the associations between geographic locations and individual works presented in project director Susan Elizabeth Gagliardi’s Senufo Unbound: Dynamics of Art and Identity in West Africa, the book published in conjunction with the Cleveland Museum of Art’s 2015-16 exhibition Senufo: Art and Identity in West Africa. Each row in the project’s flat spreadsheet recorded a reason to associate a work with a place. In most cases the place-based association was fairly straightforward, meaning a single work presented in the book was identified with a single location for a single reason. Complications arose when the project team sought to record data about a single work associated with one place for different reasons or about a single work associated with multiple places.
For example, one work listed in the project’s flat spreadsheet was associated with the town of Lataha because the sculpture was reportedly acquired there. The same work was also associated with Lataha because it appears in a photograph located to the town. The identification of the single sculpture with a single place for two different reasons yielded two records in the flat spreadsheet. The green rows in an image of the flat spreadsheet show the two records, MS_CMA_09 and MS_CMA_10, the latter referencing the same sculpture and relating it to the field photo in record MS_CMA_11.
Another complication with data management in the project’s flat spreadsheet arose when a single work was associated with an ambiguous location. The blue row in our image of the flat spreadsheet corresponds to MS_CMA_62, the record for a figure associated with Niena, a town name that, in the absence of more information, may correspond to four distinct geographic locations.
The records for the sculpture associated with Lataha and the figure associated with Niena made it clear to the project team that a flat spreadsheet could not track multiple relationships among objects, images of objects, and places without generating multiple records and thus repetitive data for a single work.
Flat spreadsheets and relational databases act as repositories for data that users can query. A flat spreadsheet stores all the data in a single table. By contrast, a relational database organizes information into multiple tables that reference one another.
When evaluating digital humanities projects, a critical first step is to focus on the data and conceptualize clearly the data structure before trying to input that data into a digital platform. Thus, before designing a relational database for Mapping Senufo, the project team regularly met to understand the information and relationships integral to the project’s goals. Through our investigation of project data and aims, we recognized that to track and manage data efficiently, including for incorporation into maps and web design, the project required a relational database. More specifically, we decided that separating distinct entities such as works and places into their own tables was necessary to track different kinds of relationships between works and places.
A major benefit of using a relational database, rather than a flat spreadsheet, to organize a large dataset, is that a relational database reduces data repetition by moving certain data into separate tables. In a flat spreadsheet, repetitive data clutters and clouds the one table. Development of separate tables within a relational database makes it possible to link a single table to additional data in secondary tables. For example, the project’s relational database now includes a single record for the sculpture reportedly acquired and photographed in Lataha (1 in Work_Records below). A table for works’ records stores information about the sculpture (Work_Records), another table for places stores information about the town (Places), and still another table lists reasons for linking specific works to particular places (Works_Places).
So, as this image from the relational database illustrates, “Photograph” is identified as one reason for connecting the Janus sculpture to Lataha, and “Acquisition” is identified as another reason for the connection. The data about Lataha from the Places table need only be entered once, and can then be associated with multiple records from the Work_Records table or multiple reasons in Works_Places. This example shows the flexibility of the relational database structure to form connections and prevent repetition of data. A more comprehensive discussion of the particular relational database structure developed for Mapping Senufo appears later in this essay.
We also aimed to create a relational database with a more flexible structure to accommodate different data types as well as new data. We accomplished this more flexible structure by creating additional fields for anticipated data types. For example, we included five different date fields in the Works table to account for variations in dating information. Because dates related to works and their locations vary from precise dates to vague information, we designed a database to accommodate four different numeric fields and a generic text field. More specifically, we used four numeric fields, “start date”, “end date”, “by date”, and “not after date”, as well as a generic text field “date information” to record information in a format other than a discrete year.
In addition, we used MySQL to create the relational database, and we designed it for easy integration into CARTO and WordPress to facilitate future development of the project. This design of a relational database with other platforms in mind allows members of the project team to add data in an efficient and consistent manner and then to export that data for transfer to CARTO or WordPress to update data presentations. This approach is consistent with the guidelines of the Emory Center for Digital Scholarship (ECDS) for developing projects that lend themselves to ongoing technical support as platforms change and that give researchers control over the maintenance and publication of their data.
We built the relational database around the early, flat spreadsheet for the project, but we also designed the relational database so it could accommodate hundreds of records as the project expands. As we worked on the relational database design, we presented multiple iterations of the database to the project team for feedback and discussion. As the project develops, we can continue to tailor the relational database to supply expanding datasets to various platforms, including CARTO and WordPress, for data presentation.
The technologies we chose to use reflect:
The selected technologies include the following:
MySQL Community Edition is an open-source Structured Query Language (SQL) database management system (see also My SQL Reference Manual / General Information). MySQL supports creation of large sustainable databases that can contain anything from small data sets with a few records to large data sets with many millions of records. MySQL also works with a variety of other platforms to make the data more flexible. As the most widely used open-source database management system, MySQL provides the benefits of a large user community that shares knowledge about logistics, trouble-shooting and best practices online. Its cost-effectiveness, flexibility, and large user community make MySQL a practical database solution.
Django is a web application framework written in Python that automatically generates an admin interface for data entry. Django’s data-entry interface provides access to MySQL databases for cataloging and presenting the data on the Internet. As an open-source platform, Django has the advantage of community-contributed packages that provide additional function and work like plugins. For Mapping Senufo, we selected the packages django-import-export (0.4.0) and django-queryset-csv (0.3.2) for export of data into CSV files that can be used by other platforms. Data from CSV files imported into CARTO can facilitate map creation. Data from CSV files imported into WordPress can populate information on pages created for individual works.
CARTO is a cloud mapping tool that allows for clear presentation of discrete locations and also interacts well with other web platforms such as WordPress.
WordPress is a tool for the creation of customizable organized websites. Its simple design and many customizable options for the presentation of digital humanities projects make WordPress a good platform for early iterations of Mapping Senufo.
Our relational database allows the Mapping Senufo team to manage, query, analyze, and publish data. The Django Admin interface makes it easy for the project team to enter data into the database and interact with it. Django-import-export and django-queryset-csv, packages of code written by members of the Django user community, integrate with the Admin and support the creation of predefined queries. Export buttons activate these queries and select specific sets of data to populate CSV files for ready import into CARTO and WordPress.
The Mapping Senufo relational database comprises five primary tables: Work_Records, Authors, Places, Images, and Works_Places. Each table captures different information, and the structure reflects a series of specific decisions to accommodate project data.
Work_Records captures specific information about individual works (objects or images) and their histories.
Authors collects data about attributed or actual creators of works. A record in this table may connect a single creator to one or more works from Work_Records or to one or more images from Images.
Places records information about specific places, including latitude and longitude. The field acquisition and provenance fields also connect to records in the Places table.
Images gathers information on digital images of works listed in the Work_Records table and other ancillary images.
The Mapping Senufo relational database also includes two supporting tables, Additional_Places and Provenance.
Additional_Places captures variant names and spellings for places in the Places table.
Provenance records data on the provenance of each work in the Work_Records table.
In addition, four linking tables support use of Many-to-Many fields by connecting multiple records in from other tables. The four tables are: Images_ImageAuthor_Name, works_places_Related_Images, Images_Works_ID, and work_records_Author.
The linking tables are not for catalogers or those querying the database to use. Many-to-Many fields rely on a linking table for their underlying structure, and these four tables allow the other major tables to have Many-to-Many fields relating works, places, and images. Stated differently, the linking tables basically function as indexes that track multiple connections between different tables. They must exist for the database to support many-to-many relationships, but a cataloguer does not need to edit them directly because the Django platform is coded to update them appropriately.
Tables in relational databases rely on two special types of fields, Primary Keys and Foreign Keys, to link to one another. A Primary Key is a unique identifier assigned to each record and is required in all tables. A Foreign Key is used to reference a related record in another table and its value is the Primary Key of the related record. As the example of the two records for a single sculpture associated with Lataha for two different reasons demonstrates, the early flat spreadsheet for Mapping Senufo tracked reasons to link works and places and not the works themselves. To resolve the creation of redundant records within the spreadsheet, we created the Works_Places table. This table contains the records that link the single sculpture to Lataha because the sculpture was reportedly acquired and photographed in the town. One Foreign Key references the record for the sculpture in the Work_Records table and another Foreign Key to reference the Places table.
The relationships between fields in different tables can be described by one of two types, One-to-Many or Many-to-Many. The early flat spreadsheet presented a problem when researchers needed to record alternate names for a single place. An example is the village Solokaha, Côte d’Ivoire and its alternate name Soloka.
The problem with using a single column for this information is that it does not allow more than one alternate name. To account for this possibility, we created a separate table called Additional Places in which each record contained a Foreign Key reference to the main Places table.
The relationship between Places and Additional_Places is One-to-Many, each place can have many alternative names, but each alternate name is associated with only one place. Another type of relationship, one that is particularly common in humanities datasets, is Many-to-Many. The relationship between works of art and the people who make them is a common example. An artwork may be produced by more than one artist and each artist may create a number of works. To accurately reflect a Many-to-Many relationship between two tables, a third linking table is needed to record each connection. There are several Many-to-Many relationships in the Mapping Senufo dataset such between works and authors, place and works, and works and images. The image below shows a case where one author is connected to two photographs in Work_Records.
With the relational database that we have created, the Mapping Senufo team is gathering data and investigating complex relationships between individual works and geographic locations in a diverse West African region. The kind of data integrity and consistency supported by relational databases could theoretically be achieved with a series of flat spreadsheets scrupulously maintained in Microsoft Excel or another similar program. Maintenance of a series of flat spreadsheets, however, would place an undue burden on researchers by dividing their attention between the subjects they care about and the cumbersome monotony of logging identifying keys. A well-designed relational database with an intuitive interface helps researchers improve and maintain the integrity of their data. It also allows for complex querying to combine and export data. This functionality helps researchers use other tools like CARTO to visualize their conclusions in compelling and interactive ways.
Joanna Mundy and Sara Palmer
23 September 2016
